Introduction
Are you curious to find out how CHAT GPT technically works? Have you heard about this revolutionary artificial intelligence technology that is changing the way we connect online. In this article, I will reveal the secrets of CHAT GPT, the virtual assistant based on Large Language Model (LLM) and Reinforcement Training from Human Feedback (RLHF).
In this guide I have collected months of tests and studies on a tool, which together with all the new things that are emerging in so-called LLMs, will change the way we work in the future.
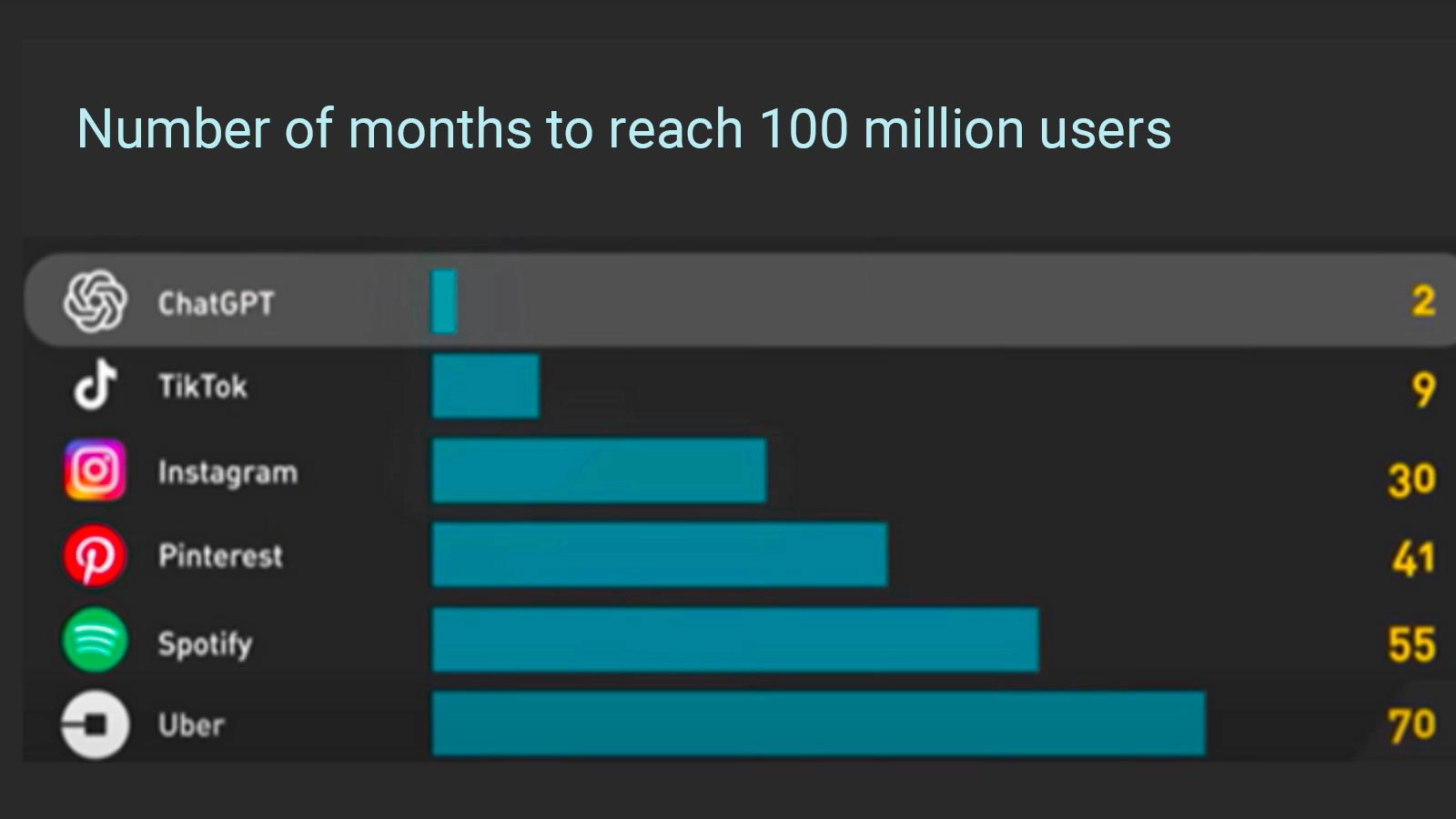
CHAT GPT was launched on November 30, 2022, surprising the world with its rapid growth. In just two months, it reached 100 million monthly active users, surpassing even Instagram, which took two and a half years to reach the same result. This makes it the fastest growing app in history. But how does CHAT GPT reach such heights of success? Let's find out together.
The core of CHAT GPT lies in the Large Language Model (LLM), specifically the GPT-3.5 model. This type of neural model is trained on huge amounts of textual data to understand and generate human language. GPT-3.5, with its 175 billion parameters distributed over 96 layers in the neural network, is one of the largest deep learning models ever created. LLMs learn statistical patterns and relationships between words in language, enabling them to predict subsequent words based on a sequence of input tokens.
But what makes an LLM so powerful? Tokens, numerical representations of words or parts of words, are used as inputs and outputs to the model. This allows for more efficient processing than using words directly.
GPT-3.5 was trained on a large Internet dataset, with a source dataset containing 500 billion tokens. In other words, the model was trained on hundreds of billions of words found in online texts. As a result, GPT-3.5 is able to generate structured text that is grammatically correct and semantically similar to the data it was trained on.
However, without proper guidance, the model could also generate results that are untrue, toxic, or reflect harmful feelings. This is where Reinforcement Training from Human Feedback (RLHF) comes in.
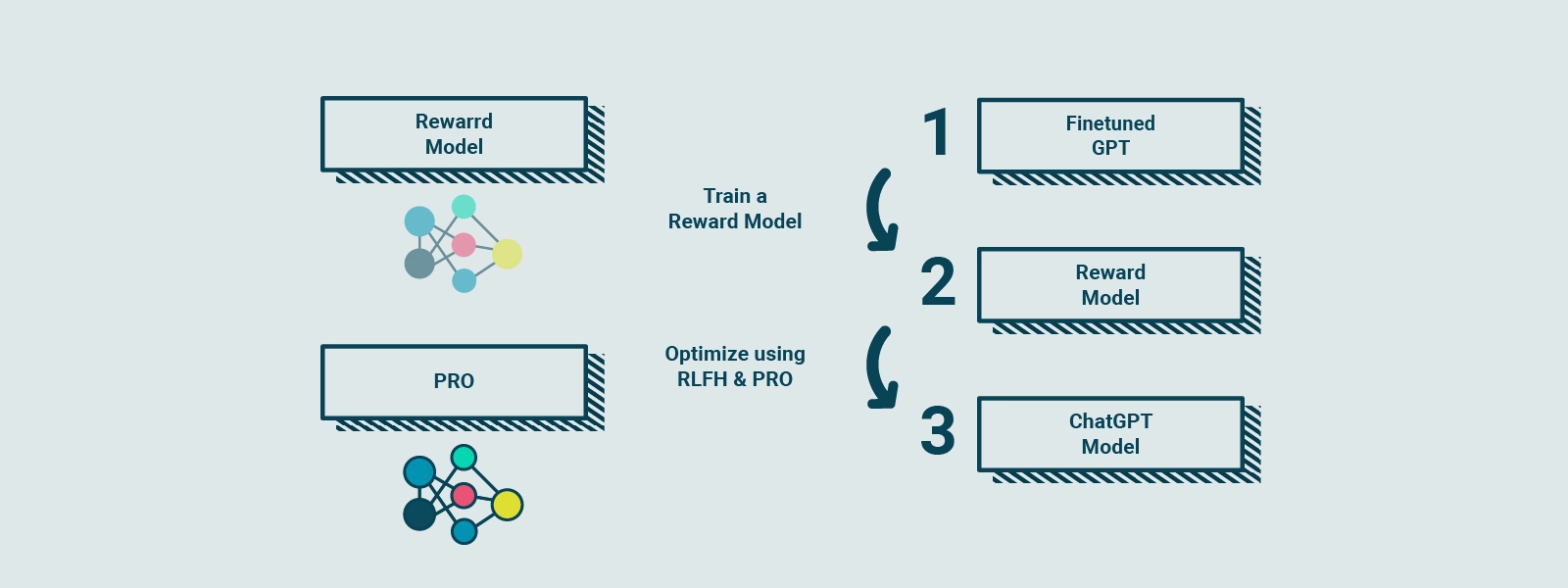
This additional training process makes the CHAT GPT model more confident and capable of answering questions consistently. RLHF is a complex process that involves collecting feedback from real people to create a "reward model," a guide that indicates users' preferences. Using a technique called Proximal Policy Optimization (PPO), the model is trained to improve its performance relative to the reward model.
What is Artificial Intelligence and why it is useful for businesses
Let's find out together what are the practical applications and future of this revolutionary technology.
Our insight

What is Artificial Intelligence and why it is useful for businesses
Let's find out together what are the practical applications and future of this revolutionary technology.
Approfondimento
History of LLMs
To fully understand how CHAT GPT works, it is essential to know the history of Large Language Models (LLMs). LLMs represent a milestone in the evolution of artificial intelligence and natural language generation.
An LLM is a type of neural network-based model that is trained on massive amounts of textual data to understand and generate human language. These models are able to learn statistical patterns and complex relationships between words in language, enabling them to predict subsequent words based on a sequence of input tokens.
In practice, an LLM breaks down text into small units, called tokens, and uses these numerical representations to process the information efficiently.
What makes LLMs particularly impressive is their size and complexity. The largest model currently available, GPT-3.5, has as many as 175 billion parameters, distributed over 96 layers in the neural network. This makes GPT-3.5 one of the largest deep learning models ever created, capable of processing and understanding vast amounts of data with extraordinary accuracy.
Training an LLM requires a large amount of textual data. GPT-3.5 was trained on a huge Internet dataset, which contains an incredible 500 billion tokens. This corresponds to hundreds of billions of words from various online sources. Through this intensive training process, the model was exposed to a wide range of texts and developed a deep understanding of human language.
The main goal of an LLM such as GPT-3.5 is to generate consistent, quality text that reflects context and has correct semantic meaning. However, it is important to note that without proper guidance, LLMs can also generate content that is untruthful, toxic, or reflects harmful sentiments. Therefore, further training through Reinforcement Training from Human Feedback (RLHF) is critical to refine the model and make it safer and more efficient in responding to users' questions.
In summary, Large Language Models (LLMs) represent a milestone in artificial intelligence and natural language generation. Their complexity, size, and ability to learn from textual data make them powerful tools for understanding and generating human language accurately. CHAT GPT, based on GPT-3.5, is an excellent example of how LLMs can be applied to create intelligent, high-performance virtual assistants.
How CHAT GPT Works
At the heart of CHAT GPT is the Large Language Model (LLM) GPT-3.5, which is currently used in the application. However, it is important to note that CHAT GPT could also benefit from the use of the newer GPT-4 model, although not much technical information about it is currently available.
GPT-3.5 underwent an intensive training process on a vast amount of Internet data. The source dataset used for training contains an incredible 500 billion tokens, which corresponds to hundreds of billions of words. During training, the model was exposed to a wide range of texts from different online sources.
The main goal of training GPT-3.5 was to teach the model to predict the next token based on a sequence of input tokens. This approach allows GPT-3.5 to generate text that is structured in a grammatically correct and semantically consistent manner with respect to the Internet data on which it was trained.
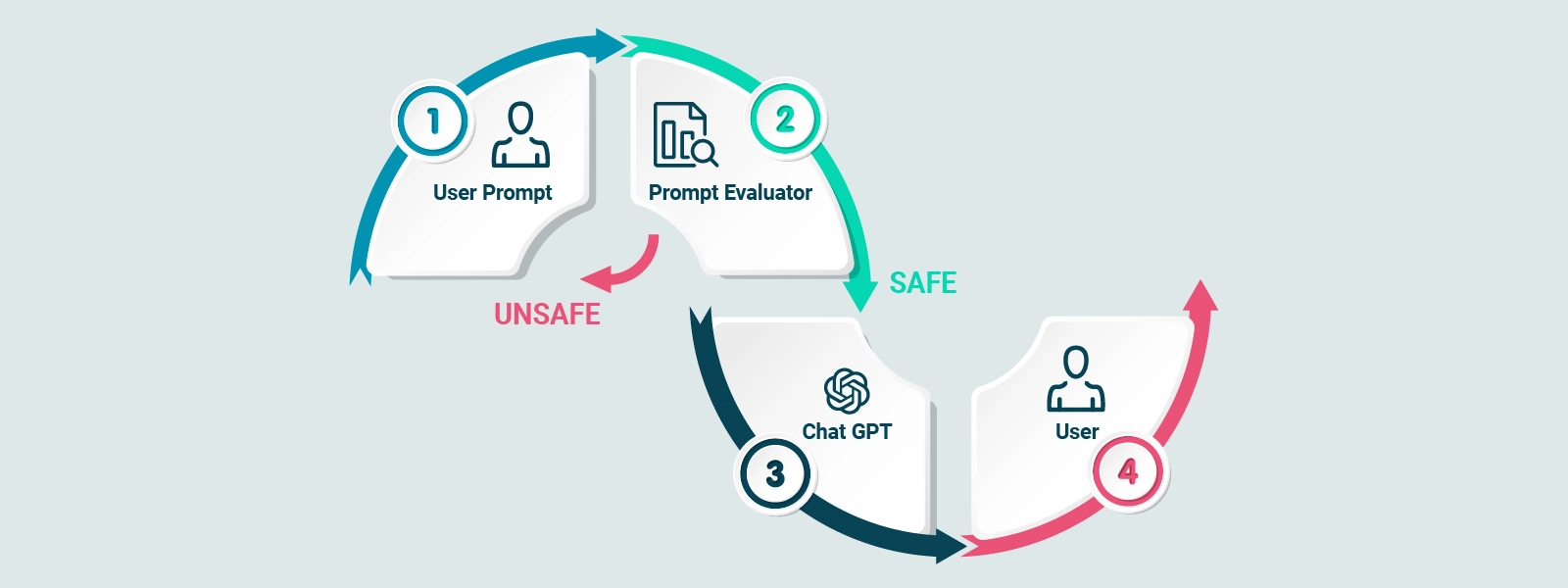
It is important to note that although GPT-3.5 can generate quality text, it is critical to provide the model with adequate guidance to avoid generating content that is untruthful, toxic, or reflects harmful sentiments.
Further refinement of the model through techniques such as Reinforcement Training from Human Feedback (RLHF) helps to improve the quality and confidence of responses generated by Chat GPT.
Reinforcement Training from Human Feedback
To make the CHAT GPT model more secure, able to provide contextual responses and interact in the style of a virtual assistant, a process called Reinforcement Training from Human Feedback (RLHF) is used. This further training process transforms the basic model into a refined model that better meets user needs and aligns with human values.
RLHF involves collecting feedback from real people to create a "reward model" based on user preferences. This reward model serves as a guide for the model during training. It is similar to a cook practicing the preparation of dishes, following a reward model based on customers' taste. The cook compares the current dish with a slightly different version and learns which version is better according to the reward model. This process is repeated several times, allowing the cook to hone his cooking skills based on updated customer feedback.
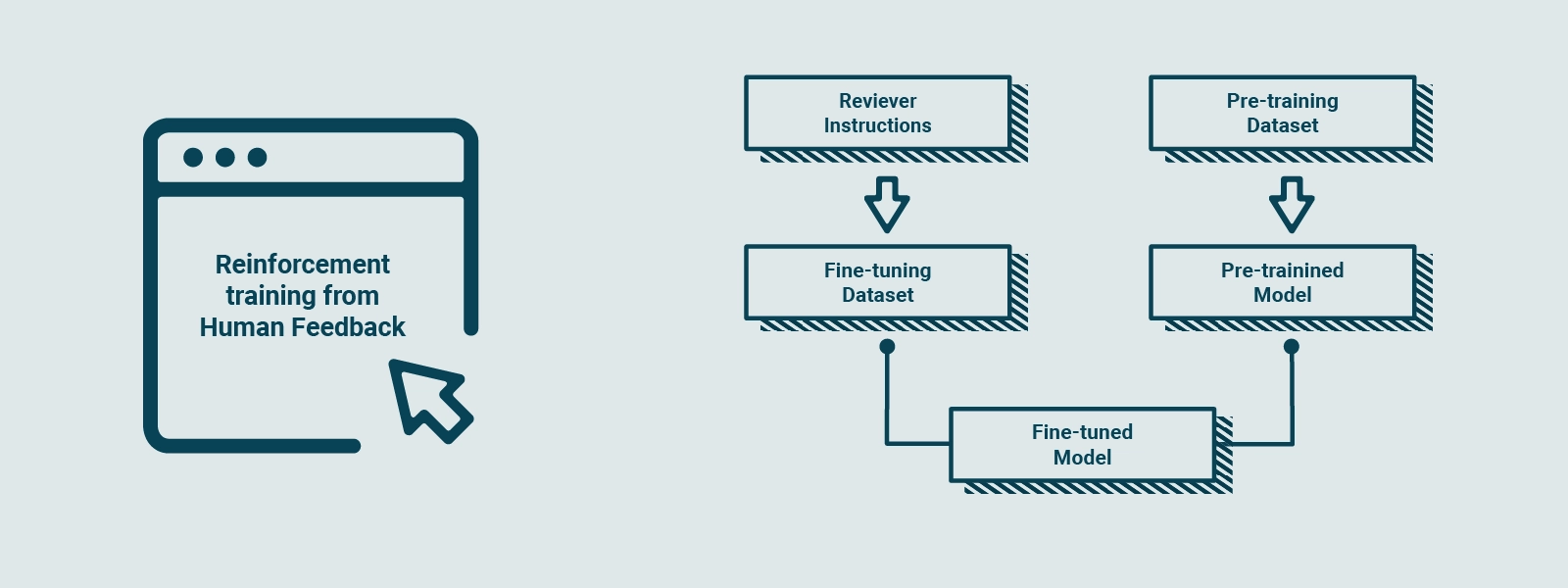
Similarly, GPT-3.5 is subjected to RLHF, collecting feedback from people to create a reward model based on their preferences. Using a technique called Proximal Policy Optimization (PPO), the model is trained to improve its performance relative to the reward model. This technique is similar to the cook comparing his current dish with a slightly different variant and learning which version is better according to the reward model. With each iteration, the model gets closer and closer to the users' preferences, generating better and more personalized responses to requests.
Through RLHF and the use of PPO, GPT-3.5 is being iteratively refined, improving its language generation abilities and adapting to the needs of users. This enables CHAT GPT to generate more accurate, consistent and relevant responses to user questions, creating a more engaging and satisfying interaction experience.
Training an LLM explained simple
OpenAI explained how it ran RLHF on the model, but it is not easy to understand for people not familiar with Machine Learning. Let's try to understand it with a simple analogy.
Suppose GPT-3.5 is a highly skilled chef who can prepare a wide variety of dishes.
Refining the model of GPT-3.5 with RLHF is like honing this chef's skills to make the most delicious dishes for his particular customers.
Initially, the chef is trained in the traditional way with a large data set of recipes and cooking techniques.
However, sometimes the chef does not know which dish to prepare for a specific customer request.
To help with this, we collect feedback from real people to create a new dataset (new recipes or variations of previous ones).
By the way, don't ask for cream in carbonara or pineapple on pizza.
The first step is to create a comparison dataset. We ask the chef to prepare multiple dishes for a given request, and then have the dishes ranked according to taste and presentation.
This helps the chef understand which dishes are preferred by customers.
The next step is reward modeling: the chef uses this feedback to create a "reward model," which is like a guide to understanding customer preferences.
The higher the reward, the better the dish.
To better understand, let us imagine that the chef is practicing the preparation of dishes following a reward guide.
It is as if the chef compares the dish he just cooked with a slightly different version and learns which dish is better, according to the reward guide.
This process is repeated many times, with the chef honing his skills based on updated feedback from customers.
Each time he repeats the process, the chef gets better and better at preparing dishes that meet customers' preferences.
A similar concept applies to GPT-3.5, which is refined with RLHF by collecting people's feedback, creating a reward guide based on their preferences, and then gradually improving the performance of the model using PPO.
PPO - Proximal Policy Optimization
PPO, which stands for Proximal Policy Optimization, is a technique used in training machine learning models. Proximal Policy Optimization is a proximal policy optimization algorithm that is used to improve the performance of neural models during the training process. This algorithm is based on the concept of gradual improvement of decision policies, controlling the changes made to existing policies so as to ensure stability in training and better convergence to optimal results.
The goal of PPO is to refine the decision policies of machine learning models, enabling them to learn from training data more efficiently. This is accomplished through a series of iterations, in which the model performs actions and compares the results with a slightly modified version of the decision policies. The algorithm evaluates the differences between the two policies and, based on those differences, updates the existing policies to bring the results closer to the desired performance.
PPO is distinguished by its ability to balance the exploration of new strategies with the use of information already learned from the model. This approach allows for better stability in training and greater efficiency in achieving optimal results. In addition, PPO offers advantages in terms of controlling changes made to decision policies, ensuring that changes are moderate and gradual, thus avoiding instability in learning and the occurrence of undesirable effects.
Conclusions
CHAT GPT represents an incredible breakthrough in artificial intelligence and natural language generation. Using LLMs such as GPT-3.5, trained on massive amounts of Internet data and subjected to RLHF, CHAT GPT is able to provide contextually relevant and semantically consistent responses to user queries.
