Introduzione
Sei curioso di scoprire come funziona tecnicamente CHAT GPT? Hai sentito parlare di questa rivoluzionaria tecnologia di intelligenza artificiale che sta cambiando il modo in cui ci connettiamo online. In questo articolo, ti svelerò i segreti di CHAT GPT, l’assistente virtuale basato su Large Language Model (LLM) e il Reinforcement Training from Human Feedback (RLHF).
In questa guida ho raccolto mesi di prove e studi su uno strumento, che insieme a tutte le novità che stanno emergendo nei cosiddetti LLM, cambieranno nel futuro il nostro modo di lavorare.
CHAT GPT è stato lanciato il 30 novembre 2022, sorprendendo il mondo con la sua rapida crescita. In soli due mesi, ha raggiunto 100 milioni di utenti attivi mensili, superando persino Instagram, che ci ha messo due anni e mezzo per raggiungere lo stesso risultato. Questo lo rende l’app in più rapida crescita nella storia. Ma come fa CHAT GPT a raggiungere tali vette di successo? Scopriamolo insieme.

Il cuore di CHAT GPT risiede nel Large Language Model (LLM), in particolare il modello GPT-3.5. Questo tipo di modello neurale è addestrato su enormi quantità di dati testuali per comprendere e generare linguaggio umano. GPT-3.5, con i suoi 175 miliardi di parametri distribuiti su 96 livelli nella rete neurale, è uno dei modelli di deep learning più grandi mai creati. I LLM apprendono i modelli statistici e le relazioni tra le parole del linguaggio, consentendo loro di prevedere le parole successive in base a una sequenza di token di input.

Ma cosa rende un LLM così potente? I token, rappresentazioni numeriche di parole o parti di parole, vengono utilizzati come input e output del modello. Ciò consente un’elaborazione più efficiente rispetto all’utilizzo diretto delle parole.
GPT-3.5 è stato addestrato su un ampio set di dati Internet, con un dataset sorgente che contiene 500 miliardi di token. In altre parole, il modello è stato addestrato su centinaia di miliardi di parole presenti in testi online. Di conseguenza, GPT-3.5 è in grado di generare testo strutturato che risulta grammaticalmente corretto e semanticamente simile ai dati su cui è stato addestrato.
Tuttavia, senza una guida adeguata, il modello potrebbe generare anche risultati non veritieri, tossici o riflettere sentimenti dannosi. È qui che entra in gioco il Reinforcement Training from Human Feedback (RLHF).
Questo processo di addestramento ulteriore rende il modello di CHAT GPT più sicuro e capace di rispondere alle domande in modo coerente. RLHF è un processo complesso che coinvolge la raccolta di feedback dalle persone reali per creare un “reward model”, una guida che indica le preferenze degli utenti. Utilizzando una tecnica chiamata Proximal Policy Optimization (PPO), il modello viene allenato per migliorare le sue prestazioni rispetto al reward model.
Storia dei LLM
Per comprendere appieno il funzionamento di CHAT GPT, è fondamentale conoscere la storia dei Large Language Model (LLM). Gli LLM rappresentano una pietra miliare nell’evoluzione dell’intelligenza artificiale e della generazione del linguaggio naturale.
Un LLM è un tipo di modello neurale basato su reti neurali che viene addestrato su enormi quantità di dati testuali per comprendere e generare linguaggio umano. Questi modelli sono in grado di apprendere i modelli statistici e le relazioni complesse tra le parole nel linguaggio, consentendo loro di predire le parole successive in base a una sequenza di token di input.
In pratica, un LLM scompone il testo in piccole unità, chiamate token, e utilizza queste rappresentazioni numeriche per elaborare le informazioni in modo efficiente.
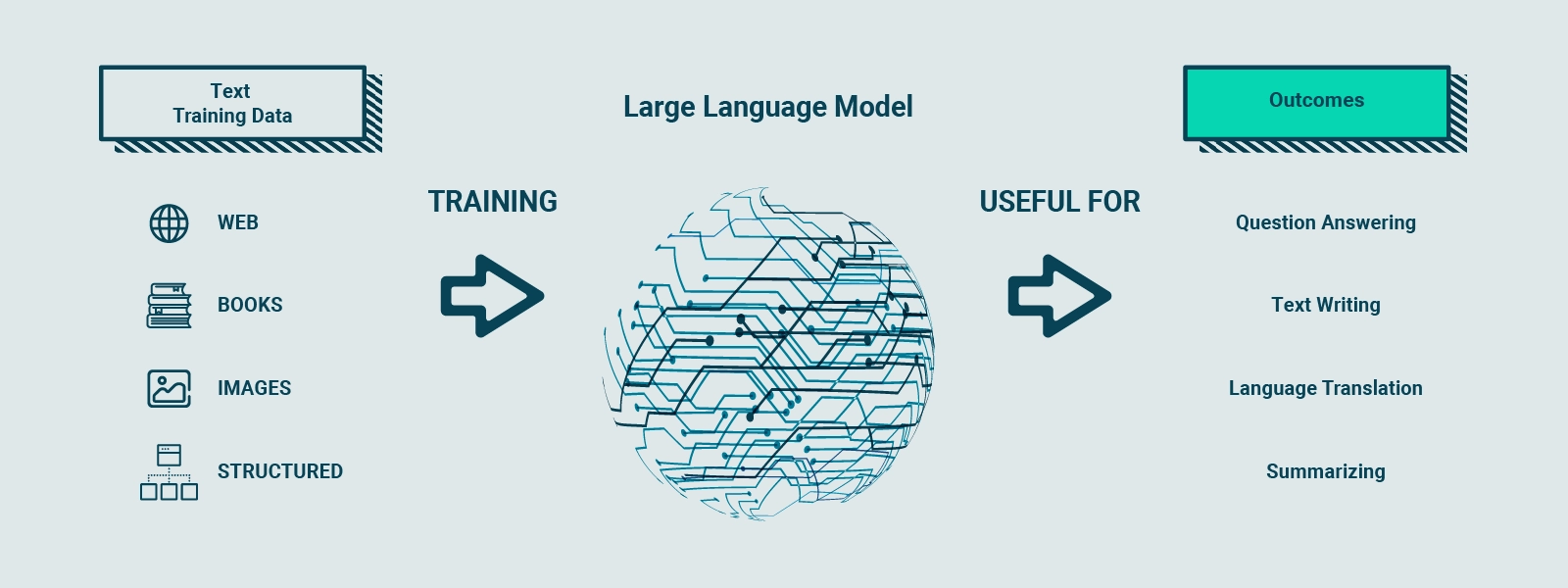
Ciò che rende i LLM particolarmente impressionanti è la loro dimensione e complessità. Il modello più grande attualmente disponibile, GPT-3.5, conta ben 175 miliardi di parametri, distribuiti su 96 livelli nella rete neurale. Questo rende GPT-3.5 uno dei più grandi modelli di deep learning mai creati, in grado di elaborare e comprendere una vasta quantità di dati con una precisione straordinaria.
L’addestramento di un LLM richiede una grande quantità di dati testuali. GPT-3.5 è stato addestrato su un enorme set di dati Internet, che contiene un incredibile numero di 500 miliardi di token. Questo corrisponde a centinaia di miliardi di parole provenienti da varie fonti online. Attraverso questo processo di addestramento intensivo, il modello è stato esposto a una vasta gamma di testi e ha sviluppato una profonda comprensione del linguaggio umano.
L’obiettivo principale di un LLM come GPT-3.5 è quello di generare testo coerente e di qualità, che rispecchi il contesto e abbia un significato semantico corretto. Tuttavia, è importante sottolineare che senza una guida adeguata, i LLM possono generare anche contenuti non veritieri, tossici o che riflettono sentimenti dannosi. Pertanto, l’ulteriore addestramento attraverso il Reinforcement Training from Human Feedback (RLHF) è fondamentale per perfezionare il modello e renderlo più sicuro ed efficiente nel rispondere alle domande degli utenti.
In sintesi, i Large Language Model (LLM) rappresentano una pietra miliare nell’ambito dell’intelligenza artificiale e della generazione del linguaggio naturale. La loro complessità, dimensione e capacità di apprendimento dai dati testuali li rendono strumenti potenti per comprendere e generare il linguaggio umano in modo accurato. CHAT GPT, basato su GPT-3.5, è un esempio eccellente di come i LLM possono essere applicati per creare assistenti virtuali intelligenti e altamente performanti.
Come Funziona CHAT GPT
Il cuore di CHAT GPT è rappresentato dal Large Language Model (LLM) GPT-3.5, attualmente utilizzato nell’applicazione. Tuttavia, è importante sottolineare che CHAT GPT potrebbe anche beneficiare dell’utilizzo del più recente modello GPT-4, anche se al momento non sono ancora disponibili molte informazioni tecniche su di esso.
GPT-3.5 è stato sottoposto a un intenso processo di addestramento su una vasta quantità di dati Internet. Il dataset sorgente utilizzato per l’addestramento contiene un incredibile numero di 500 miliardi di token, che corrisponde a centinaia di miliardi di parole. Durante l’addestramento, il modello è stato esposto a una vasta gamma di testi provenienti da diverse fonti online.
L’obiettivo principale dell’addestramento di GPT-3.5 è stato quello di insegnare al modello a prevedere il token successivo in base a una sequenza di token di input. Questo approccio consente a GPT-3.5 di generare testo che risulta strutturato in modo grammaticalmente corretto e semanticamente coerente rispetto ai dati Internet su cui è stato addestrato.
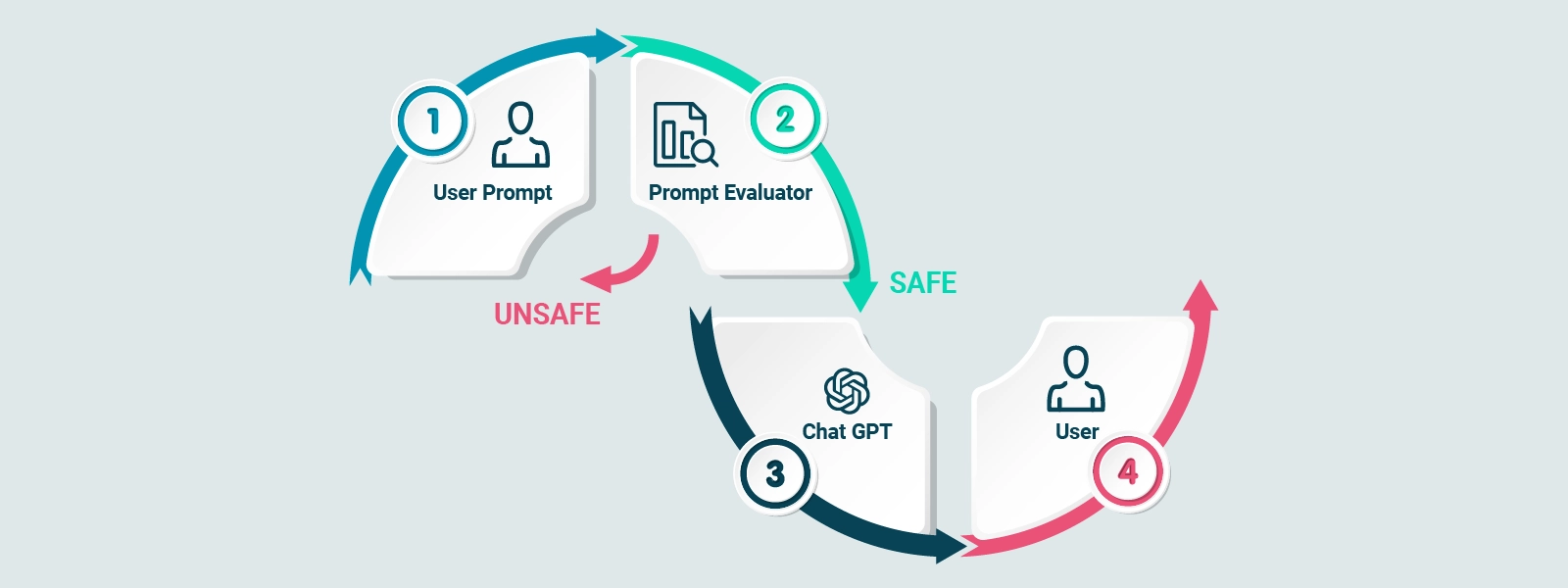
È importante notare che, sebbene GPT-3.5 sia in grado di generare testo di qualità, è fondamentale fornire al modello una guida adeguata a evitare la generazione di contenuti non veritieri, tossici o che riflettano sentimenti dannosi.
L’ulteriore affinamento del modello attraverso tecniche come il Reinforcement Training from Human Feedback (RLHF) aiuta a migliorare la qualità e la sicurezza delle risposte generate da CHAT GPT.
Reinforcement Training from Human Feedback
Per rendere il modello di CHAT GPT più sicuro, in grado di fornire risposte contestuali e di interagire nello stile di un assistente virtuale, viene utilizzato un processo chiamato Reinforcement Training from Human Feedback (RLHF). Questo processo di addestramento ulteriore trasforma il modello di base in un modello raffinato che risponde meglio alle esigenze degli utenti e si allinea ai valori umani.
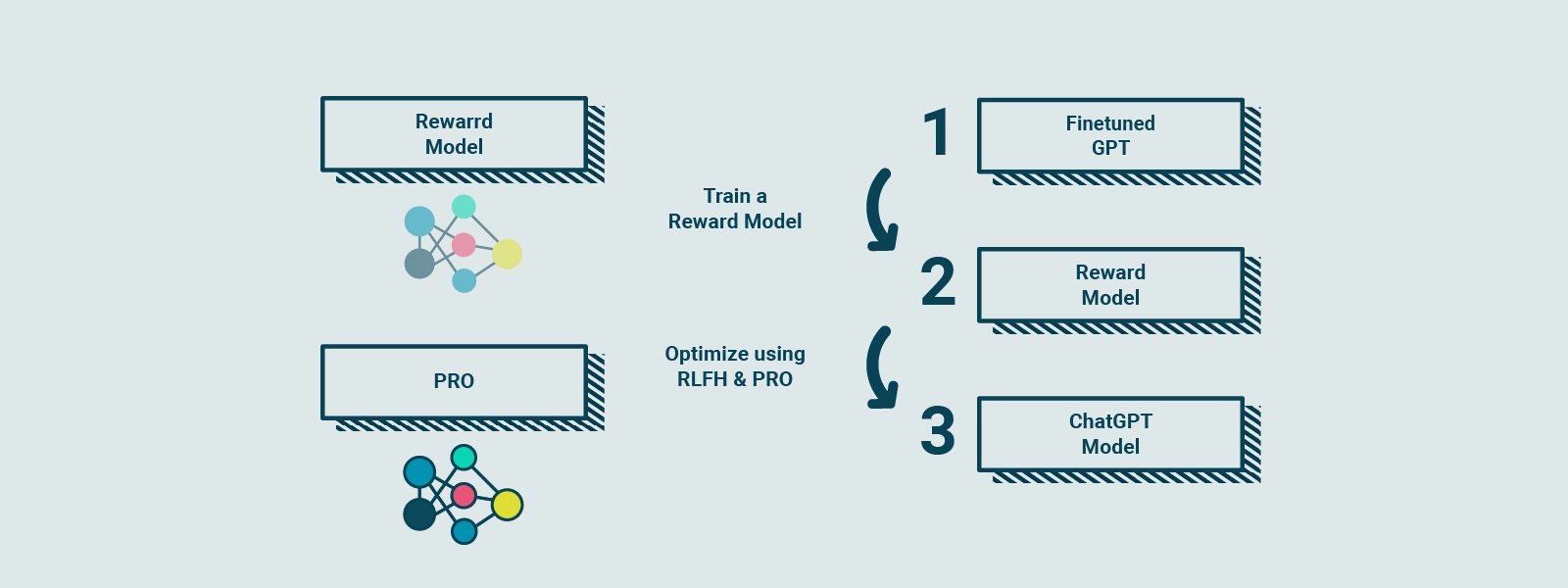
RLHF coinvolge la raccolta di feedback da persone reali per creare un “reward model” basato sulle preferenze degli utenti. Questo reward model funge da guida per il modello durante l’addestramento. È simile a un cuoco che pratica la preparazione di piatti, seguendo un modello di ricompensa basato sul gusto dei clienti. Il cuoco confronta il piatto attuale con una versione leggermente diversa e impara quale versione è migliore secondo il reward model. Questo processo viene ripetuto diverse volte, consentendo al cuoco di affinare le sue abilità culinarie basandosi sui feedback aggiornati dei clienti.

In modo simile, GPT-3.5 viene sottoposto a RLHF, raccogliendo feedback dalle persone per creare un reward model basato sulle loro preferenze. Utilizzando una tecnica chiamata Proximal Policy Optimization (PPO), il modello viene allenato per migliorare le sue prestazioni rispetto al reward model. Questa tecnica è simile al cuoco che confronta il suo piatto attuale con una variante leggermente diversa e apprende quale versione è migliore secondo il reward model. Con ogni iterazione, il modello si avvicina sempre di più alle preferenze degli utenti, generando risposte migliori e più personalizzate alle richieste.
Attraverso RLHF e l’utilizzo di PPO, GPT-3.5 viene perfezionato iterativamente, migliorando le sue abilità di generazione del linguaggio e adattandosi alle esigenze degli utenti. Ciò consente a CHAT GPT di generare risposte più accurate, coerenti e pertinenti alle domande degli utenti, creando un’esperienza di interazione più coinvolgente e soddisfacente.
L’addestramento di un LLM spiegato semplice
OpenAI ha spiegato come ha eseguito RLHF sul modello, ma non è facile da capire per le persone non esperte di Machine Learning. Proviamo a capirlo con un’analogia semplice.
Supponiamo che GPT-3.5 sia uno chef altamente qualificato in grado di preparare un’ampia varietà di piatti.
Raffinare il modello di GPT-3.5 con RLHF è come affinare le abilità di questo chef per rendere i piatti più deliziosi per i suoi particolari clienti.
Inizialmente, lo chef viene formato in maniera tradizionale con un ampio set di dati di ricette e tecniche di cottura.
Tuttavia, a volte lo chef non sa quale piatto preparare per una specifica richiesta del cliente.
Per aiutarlo in questo, raccogliamo feedback da persone reali per creare un nuovo set di dati (nuove ricette o varianti delle precedenti).
A proposito non chiedete la panna nella carbonara o l’ananas sulla pizza.
Il primo passaggio consiste nel creare un set di dati di confronto. Chiediamo allo chef di preparare più piatti per una determinata richiesta, e quindi di far classificare i piatti in base al gusto e alla presentazione.
Questo aiuta lo chef a capire quali piatti sono preferiti dai clienti.
Il prossimo passo è la modellazione della ricompensa: lo chef utilizza questo feedback per creare un “modello di ricompensa”, che è come una guida per comprendere le preferenze dei clienti.
Più alta è la ricompensa, migliore è il piatto.
Per comprendere meglio, immaginiamo che lo chef stia praticando la preparazione dei piatti seguendo una guida di ricompensa.
È come se lo chef confrontasse il piatto che ha appena cucinato con una versione leggermente diversa e imparasse quale piatto è migliore, secondo la guida di ricompensa.
Questo processo viene ripetuto molte volte, con lo chef che affina le sue abilità basandosi sul feedback aggiornato dei clienti.
Ogni volta che ripete il processo, lo chef diventa sempre più bravo a preparare piatti che soddisfano le preferenze dei clienti.
Un concetto simile si applica anche a GPT-3.5, che viene perfezionato con RLHF raccogliendo il feedback delle persone, creando una guida di ricompensa basata sulle loro preferenze e quindi migliorando gradualmente le prestazioni del modello utilizzando PPO.
PPO – Proximal Policy Optimization
PPO, acronimo di Proximal Policy Optimization, è una tecnica utilizzata nell’addestramento dei modelli di apprendimento automatico. Proximal Policy Optimization è un algoritmo di ottimizzazione delle politiche prossimali che viene impiegato per migliorare le performance dei modelli neurali durante il processo di addestramento. Questo algoritmo si basa sul concetto di miglioramento graduale delle politiche di decisione, controllando le variazioni apportate alle politiche esistenti in modo da garantire una stabilità nell’addestramento e una migliore convergenza verso risultati ottimali.
L’obiettivo di PPO è quello di affinare le politiche di decisione dei modelli di apprendimento automatico, consentendo loro di apprendere dai dati di addestramento in modo più efficiente. Questo viene realizzato attraverso una serie di iterazioni, in cui il modello esegue azioni e confronta i risultati con una versione leggermente modificata delle politiche di decisione. L’algoritmo valuta le differenze tra le due politiche e, sulla base di tali differenze, aggiorna le politiche esistenti in modo da avvicinare i risultati alle performance desiderate.
PPO si distingue per la sua capacità di bilanciare l’esplorazione di nuove strategie con l’utilizzo delle informazioni già apprese dal modello. Questo approccio consente una migliore stabilità nell’addestramento e una maggiore efficienza nel raggiungimento di risultati ottimali. Inoltre, PPO offre vantaggi in termini di controllo delle variazioni apportate alle politiche di decisione, garantendo che le modifiche siano moderate e graduale, evitando così l’instabilità nell’apprendimento e l’insorgenza di effetti indesiderati.